
Elevate your audio automatization QA/QC processes with WitScript
Our continuous evolution and reputation make us the go-to choice in the market, providing unmatched automation and quality assurance.
WitSound Technologies uses Automatic Speech Recognition (ASR) deep learning/ AI models as a fundamental element of our technology stack. ASR models are specifically designed to transcribe spoken language into written text.On the other hand, Large Language Models (LLMs), like OpenAI’s GPT, concentrate on generating coherent and contextually appropriate text. LLMs are tools that can be employed for various natural language understanding tasks. In contrast, ASR models are specifically tailored to cater to speech recognition applications.
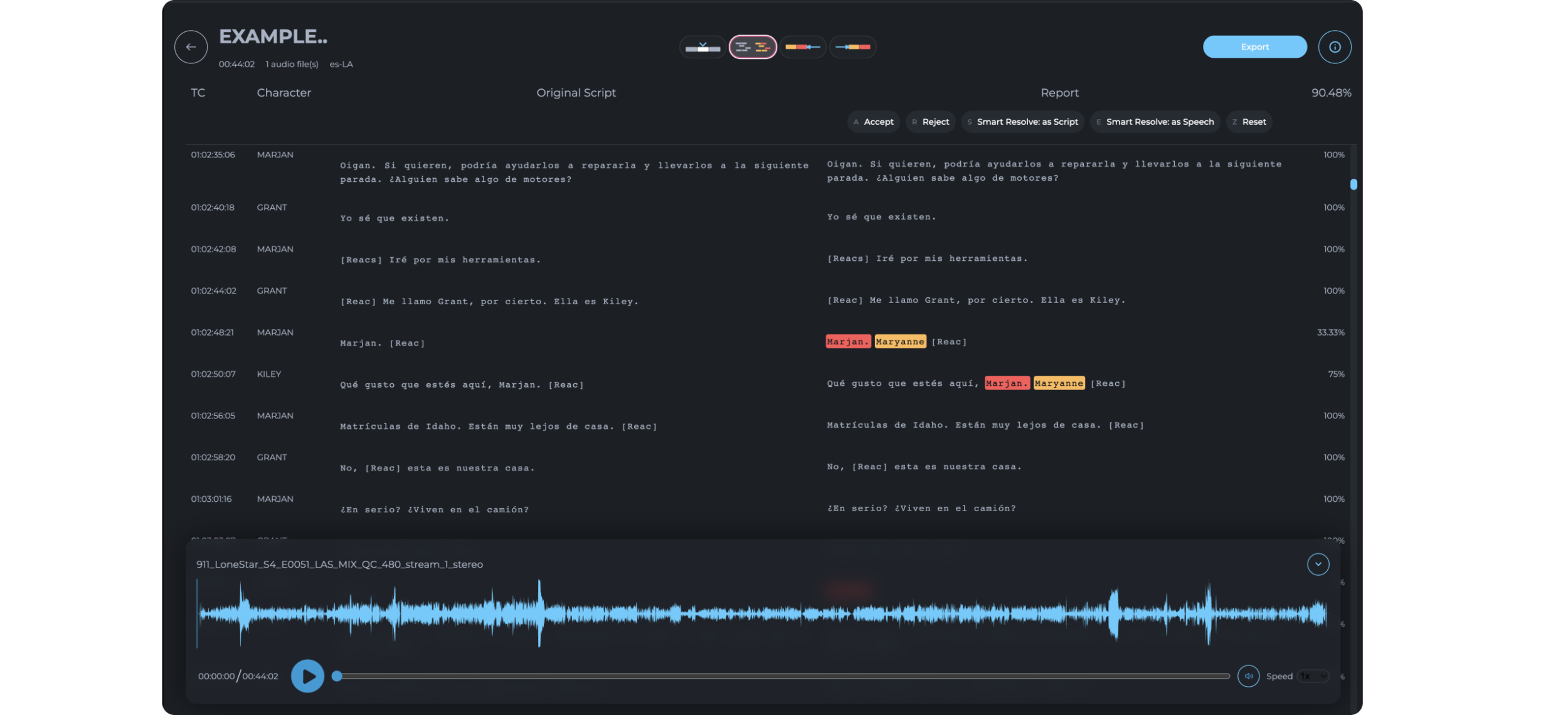


Increase the quality and speed of your internal processes with WitScript. Our software automates over 75% of the QA/QC voice over tasks, saving valuable time.
WitScript includes an editing mode that will leave you speechless. Think Microsoft Word on steroids! But that’s not all—our optimized deep learning algorithms with their lightning-fast speed and an accuracy rate of up to 88% for full mix audio. And for non-full mix audio (ADR) ? an accuracy rate of approximately 94%!





WitScript supports single or multiple audio files with all characters, whether it’s VO Stem, Full ADR, or Full Mix.
WitScript supports a wide range of audio formats and is compatible with wav files with up to 512 channels. It marks discrepancies between the original script and recorded audio, streamlining the QA/QC process.
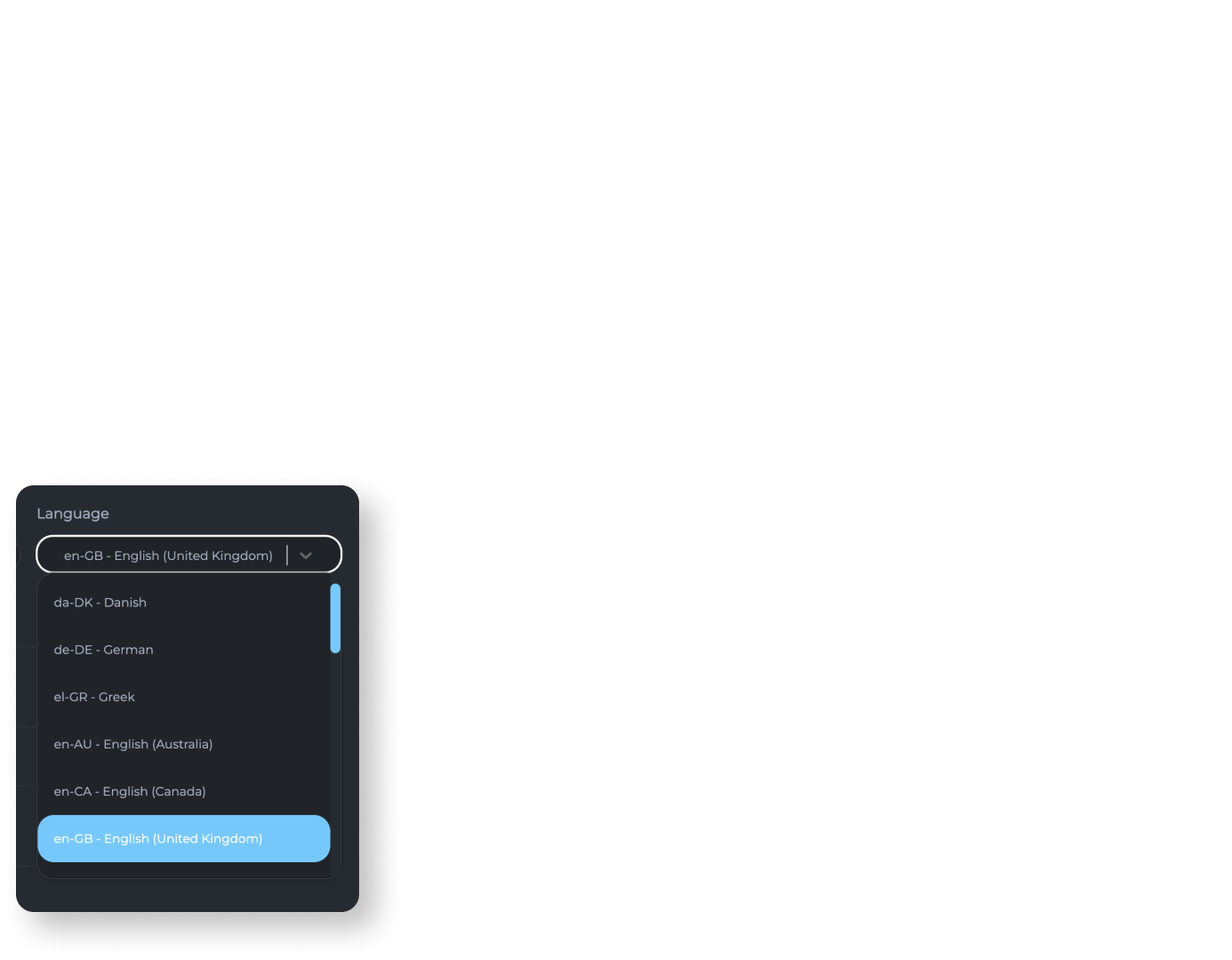
WitScript supports 32 languages: English, German, Spanish, French, Hindi, Tamil, Italian, Bulgarian, Croatian, Czech, Danish, Dutch, Estonian, Finnish, Galician, Greek, Hungarian, Indonesian, Latvian, Lithuanian, Malay, Norwegian (Bokmål), Polish, Portuguese, Romanian, Russian, Slovakian, Slovenian, Swedish, Turkish, Catalan and Vietnamese.

Only 8,99€ per 1 hour of run time audio
Contact us for more info and a demo:
You can trust on us!
We are under TPN GOLD certificate, guaranteeing
a secure and reliable solution